|
|
 |
PyEmofUCMDE/EMOF environment implemented with PythonJ.M. Drake, P. López Martínez and C. CuevasSoftware
Engineering and
Real-Time Group
(ISTR) - University
of Cantabria
|
The environment has been implemented using the Python language and thereby, it is:
The design of the PyEmofUC environment
targets the following specific features:
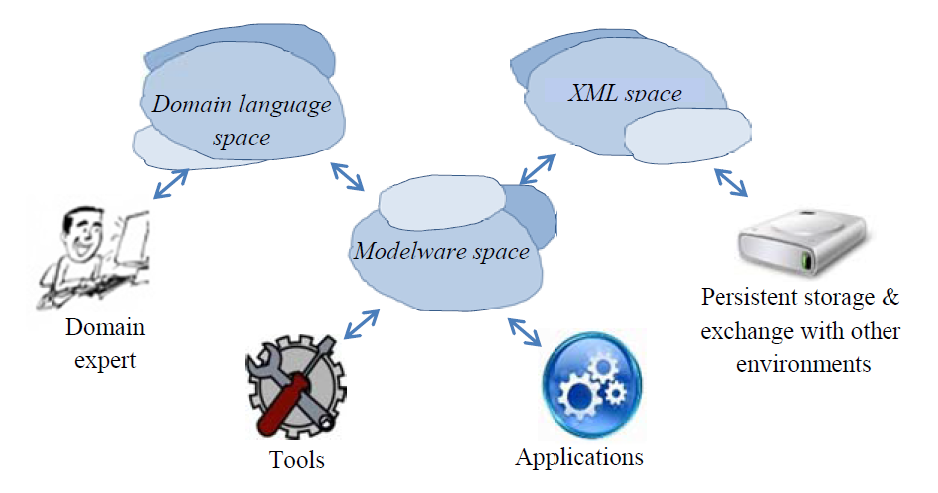
- Modelware space: It is the native technological space of the environment. The information is represented by means of Python data structures that closely match the object structures proposed by the EMOF specification. This space is the basic form of data representation that is accessible from the code of applications and tools.
- XML space: The information is represented by tagged XMI text and the references to internal and external elements are formulated through standard textual URIs.
The environment uses this space for storing models in persistent repositories and for exchanging information with other enviroments.- Domain-specific languages space: The information is represented by a domain-specific language automatically generated by the environment from the corresponding meta-model.
This space aims at facilitating the interaction with the domain expert who will formulate the information using a smart editor or will supervise it on a console.
It does
not require additional code generation: The applications operate directly on
models already present in the environment and
without previously requiring the generation of source code
for models instantiation.
Loading a model requires preload of its meta-model
and the data structures required by the application
are dynamically generated at runtime, with information
provided by the meta-model.
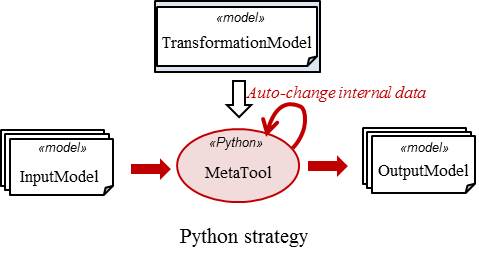
Transformations
can be formulated in an imperative or
declarative style: The model
transformations are formulated as Python scripts
using an imperative, declarative or hybrid
style.
Python is a procedural,
object-oriented and functional language.
EmofUC
extends EMOF by adding some new capabilities: The meta-models are formulated
according to the EmofUC meta-meta-model,
which constitutes an extension
of the EMOF 2.4 OMG specification in order to
facilitate its implementation with Python.
The extensions are accomplished using the tag
proposals in EMOF and define the following
aspects:
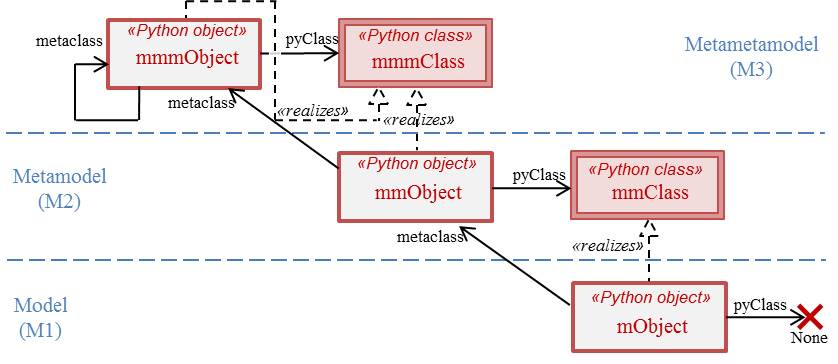
Full reflectivity provided: Every model element has direct access to its meta-class and thus to the information describing its characteristics. Reflectivity is a key feature for the creation of data structures for representing model elements during application execution. It also allows the development of model management tools regardless if the corresponding meta-models were unknown at development time.
Model management (AppRepository API)
: The
application repository (AppRepository)
is responsible for the in-memory storage of the models
on which an application works.
It is often called application enviroment.
Its public interface elements are:
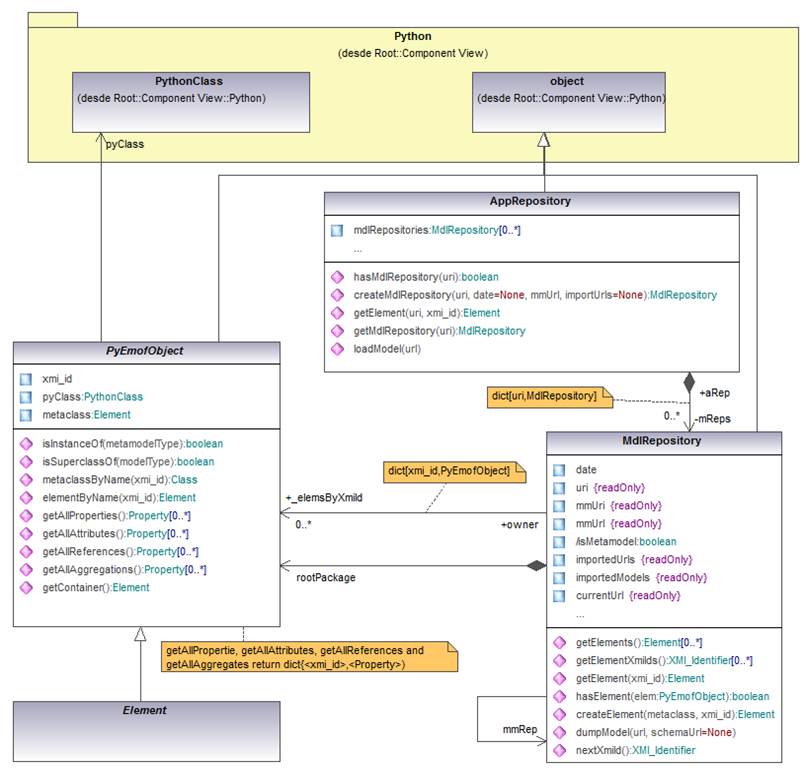
Management of
model elements (MdlRepository API): The model
repository stores the model elements.
It is often called model.
Its public interface elements are:
Management of
attributes of the enviroment itself (PyEmofObject): PyEmofObject
is the root class of all EmofUC elements. It
provides the attributes that the PyEmofUC
environment requires for managing model elements.
It defines the following reflective operations, inherited by all elements.
Management of model data (EMOF::Element and its specialized classes): Model data is formulated as a structure of aggregated elements and by means of the values assigned to their properties. On the other hand, a model behavior is formulated through the operations declared in the classes of its elements. The specialized classes of EMOF. Element are implemented as Python classes with the following characteristics:
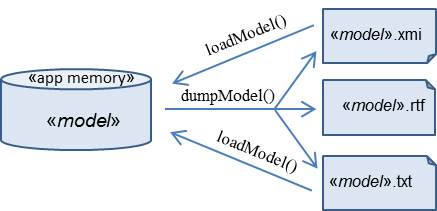
When a model is managed outside from an application memory space, it is represented by a text consisting of standard alphanumeric characters and where references are formalized as URIs (hyper-references) and the models are accessed via URL locators. The textual formulation is useful in the following cases:
Model serialization and deserialization (model creation from
textual formulation) are performed through the dump()
and loadModel() operations of the public interface.
Three serialization formats are used, namely:
The full code for the PyEmofUC
environment can be downloaded as a ZIP archive (PyEmofUC_0_0.zip).
Along with the environment code (src folder), this ZIP
archive includes a set of W3C-schemas for meta-model edition (schemas
folder), and some stuff (data and scripts) related to the CountyCity
example used for demonstration purposes (CountyCity
folder).
Below there is an outline of the PyEmofUC
environment once installed.
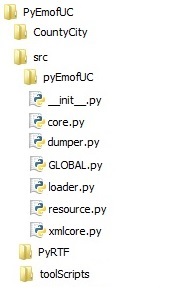 |
PyEmofUC => It is the
resultant root folder after unpacking the ZIP
archive PyEmofUC_0_0.zip. It is used as
origin for relative paths. CountyCity => Root folder of the CountyCity example, which is used to show the capabilities of PyEmofUC. src => Root Folder of the Python code of the PyEmofUC environment. Its path is included in the PYTHONPATH environment variable. pyEmofUC => Python package with the code of the PyEmofUC environment. __init__.py => Initialization module of the python package. core.py => Code supporting the meta-meta-model EmofUC. dumper.py => Code for the textual serialization of models and meta-models GLOBAL.py => Python module with the constant and global resources of the environment. loader.py => Code for loading models and meta-models from its textual formulations. resource.py => Python code for implementating the models repositories. xmlcore.py => Auxiliar code for location and access to models and meta-models formuled as XML files. PyRTF => Legacy Phyton package with resources for managing text in RTF format. toolScripts => Python package with utility scripts provided by the PyEmofUC environment. |
An MDE application operating within the PyEmofUC
environment must first create an application repository, which
is done by invoking the AppRepository() constructor.
Then, using the environment public
interface, the application can load, transform and display
models.
One application may create multiple
repositories, but every set of models with cross-references
between them must be loaded in the same one.
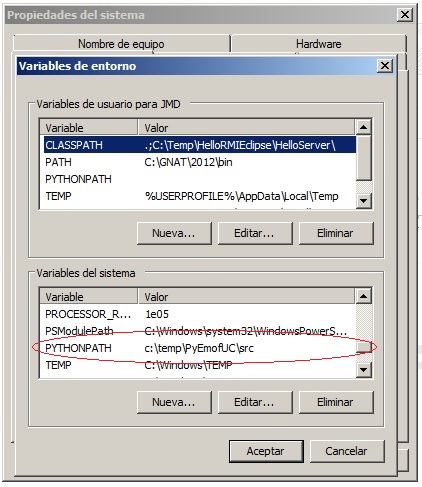
If locations use relative URLs (format "platform:
..."), the user must previously assign to the variable xml
core.PLATFORM the root folder absolute address.
In the following examples, the address "c:\temp\PyEmofUC" is
assigned as root path for relative locators:
|
>>>
import emofUC.resource as resource >>>
import EmofUC.xmlcore as xmlcore >>>
aRep=resource.AppRepository() >>>
xmlcore.PLATFORM='c:/temp/PyEmofUC' >>> |
|
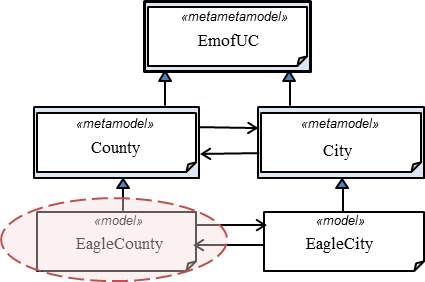
>>>
aRep.loadModel('platform:CountyCity/EagleCounty.xmi') <emofUC.resource.MdlRepository
object at 0x0000000002E8D9E8> >>> |
In this example, the load of the EagleCounty model has also required the load of the EmofUC meta-meta-model as well as the County meta-model but also the EagleCity model along with its corresponding City meta-model, because there are inter-references among the two models.
|
>>>
for key in
aRep.getMdlRepositories().keys(): print "- "+key -
http://unican.es/istr/PyEmofUC/CountyCity/EagleCounty -
http://unican.es/istr/PyEmofUC/EmofUC -
http://unican.es/istr/PyEmofUC/CountyCity/City -
http://unican.es/istr/PyEmofUC/CountyCity/County -
http://unican.es/istr/PyEmofUC/CountyCity/EagleCity >>> |
A Python application can create a model, provided that the corresponding meta-model is preloaded within the same application repository.
The following code creates a model (named newCity) compliant to the City meta-model of the CountyCity project.
|
>>> print
aRep.hasMdlRepository('http://unican.es/istr/PyEmofUC/CountyCity/City') True >>> newModel =
aRep.createMdlRepository(
'http://unican.es/istr/PyEmofUC/CountyCity/Example/newModel',
'platform:CountyCity/City.xmi',
'nme') >>> >>>
newModel.rootPackage = newModel.createElement(
'cty.CompanyDirectory',
'Id_' + str(newModel.nextXmiId())) >>> >>> aCompany =
newModel.createElement('cty.Company', 'Id_' +
str(newModel.nextXmiId())) >>>
newModel.rootPackage.company.append(aCompany) >>> aCompany.name =
'TransAtlantic Ltd.' >>> >>> aEmploy =
newModel.createElement('cty.Employ', 'Id_' +
str(newModel.nextXmiId())) >>> aEmploy.name =
'Director' >>> aEmploy.salary =
87300.00 >>> aEmploy.employer =
aCompany >>> aEmploy.worker =
None >>>
aCompany.employ.append(aEmploy) >>> >>> aEmploy =
newModel.createElement('cty.Employ', 'Id_' +
str(newModel.nextXmiId())) >>> aEmploy.name =
'Sailor' >>> aEmploy.salary =
16100.00 >>> aEmploy.employer =
aCompany >>> aEmploy.worker =
None >>>
aCompany.employ.append(aEmploy) >>> >>>
newModel.dump('platform:CountyCity/DumpedFiles/newModel.rtf') >>> |
# Check that
the mm is loaded # A new
model is created: # - The
assigned URI # - The URL of
the metamodel # - The mame
space prefix # The root
repository element is created # An element
of Company type is created # The root
repository element are added # A value is
assignet to name attribute # An
elenment of Employ type is created # The values
are assigned to attributtes # Its added
to the owner element # A second
Employ element is created # The newModel is
stored according its URL |
The table below shows the created model formulated in the RTF format ('platform:CountyCity/DumpedFiles/newModel.rtf').
|
MODEL date:2015-03-16T10:44 uri:http://unican.es/istr/PyEmofUC/CountyCity/Example/newModel mmUrl:platform:CountyCity/City.xmi nsPrefix:nme rootType: :CompanyDirectory[Id_0]{ TransAtlantic
Ltd.:Company[Id_1]{ Director:Employ[Id_2]{ salary:87300.0 worker:None employer:#Id_1 } # Director Sailor:Employ[Id_3]{ salary:16100.0 worker:None employer:#Id_1 } # Sailor } # TransAtlantic Ltd. } # |
However, the generated schema is lax and only assists the operator in certain aspects. For instance:
In the current version, the editor does not help when assigning references, since they are implemented by means of the generic xsd: anyURI type.
The figure below shows the Altova XMLSpy XML editor used for generating a model.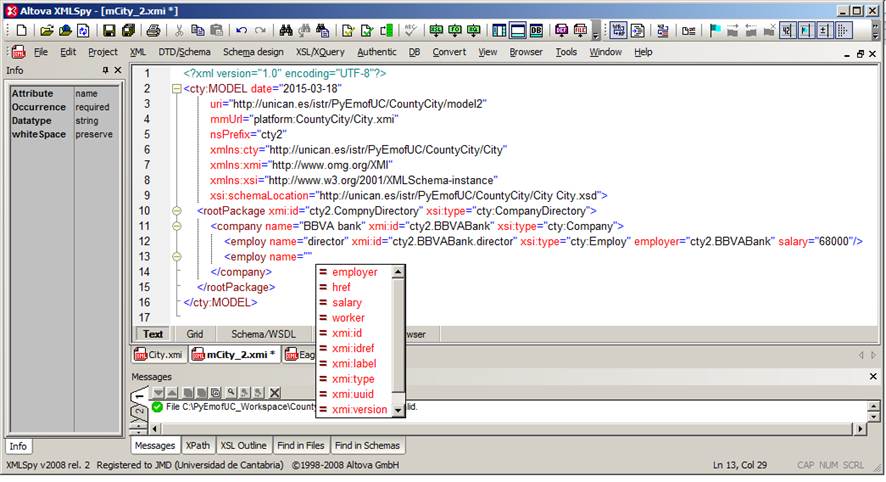
When a meta-model is stored in XMI format (e.g. City.xmi), the dump() method also generates and stores the grammar corresponding to it.
The environment provides an editor based on that grammar that assists the operator when formulating the model in textual format. This editor has not been implemented yet. (TODO)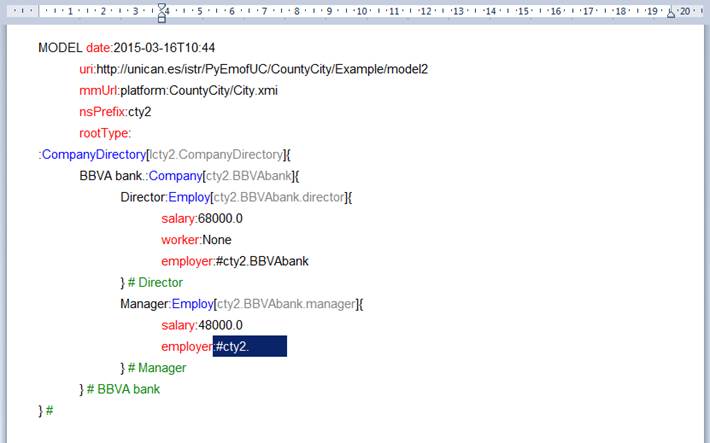
Creation, transformation and processing of
models are usually done at application memory level using a
model repository, remaining there while the application is
running.
Upon request, the model is stored in textual or XMI format using
a persistent repository. The persistence is performed using the
dump(«url») method provided
by the public interface of the MdlRepository
class.
The following code persists the model with uri = ‘http://unican.es/istr/PyEmofUC/CountyCity/EagleCounty’
in the file with url =’platform:CountyCity/DumpedFiles/EagleCounty.xmi’.
|
>>>
model=aRep.getMdlRepository('http://unican.es/istr/PyEmofUC/CountyCity/EagleCounty') >>> model.dump(url='platform:CountyCity/DumpedFiles/EagleCounty.xmi',schemaUrl='../../County.xsd') >>> |
The operator can visualize a model in three formats:
In the current version, the visualization is performed by invoking the corresponding editor on the model file. Previously, the text file must be stored using the dump() method offered by the public interface of the MdlRepository class.
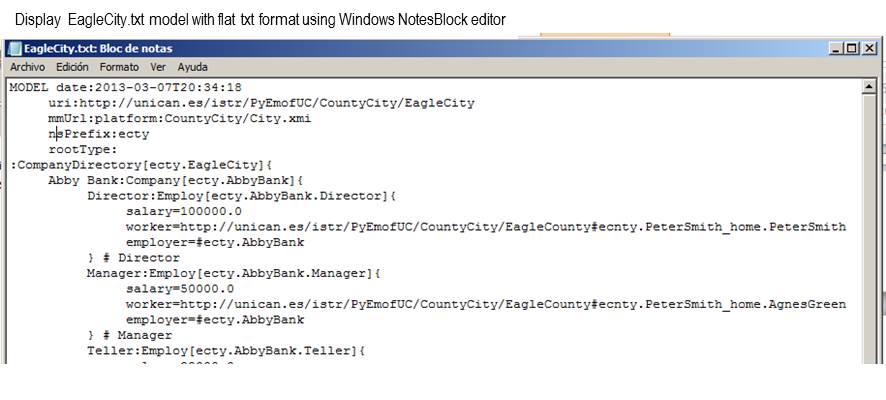
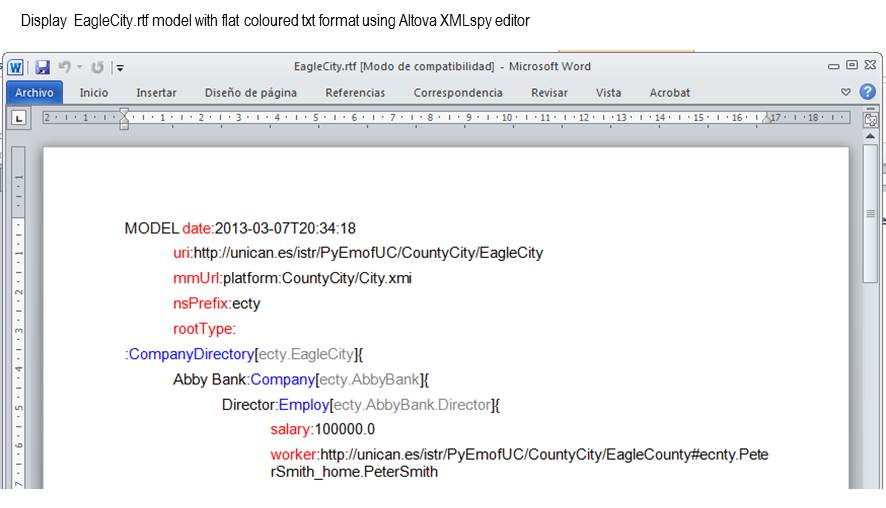
The dump() method generates the required output format according to the corresponding URL extension: ".xmi" is used if the XMI format is the desired one, while for the plain text format the ".txt” is required.The table
below shows the code for generating the EagleCity model files in
the three formats whereas the following snapshots show the use
of commercial editors compatible with the formats.
|
>>>
eagleCityModel=aRep.getMdlRepository('http://unican.es/istr/PyEmofUC/CountyCity/EagleCity') >>> # Store file with XMI format >>>
eagleCityModel.dump(url='platform:CountyCity/DumpedFiles/EagleCity.xmi',schemaUrl='../../City.xsd') >>> # Store file with flat text
format >>>
eagleCityModel.dump(url='platform:CountyCity/DumpedFiles/EagleCity.txt') >>> # Store file with flat
coloured text format >>>
eagleCityModel.dump(url='platform:CountyCity/DumpedFiles/EagleCity.rtf') >>> |
An imperative model transformation uses loops and conditional statements for selectively traversing the input model, generating output elements according to the encountered input one. In PyEmofUC this is done with a Python program using its procedural and object oriented styles.
An example of imperative transformation in
the context of the CountyCity
sample project can be found at CountyCity_CountyToTaxCensus_Imperative_script.py.
Using a declarative style, a model transformation is a two-step process.
A transformation engine successively iterates over the set of input elements generating the corresponding output elements. In PyEmofUC this is done by means of a Python program in two steps:
An example of a declarative model
transformation applied to the CountyCity
sample project is
CountyCity_CountyToTaxCensus_Declarative_script.py.
For the transformation
specification, a style similar to the one used in ATL is used.
The deletion of a single model is not yet supported in the current version of PyEmofUC.
|
>>> del aRep >>> |